A neuron is a very basic classifier. It takes a number of input signals (a feature vector) and outputs a single value (a prediction). A neuron is also a basic building block of neural networks, and by combining together many neurons we can build systems that are capable of learning very complicated patterns. This is part 2 of an introductory series on neural networks. If you haven’t done so yet, you might want to start by learning about the background to neural networks in part 1.
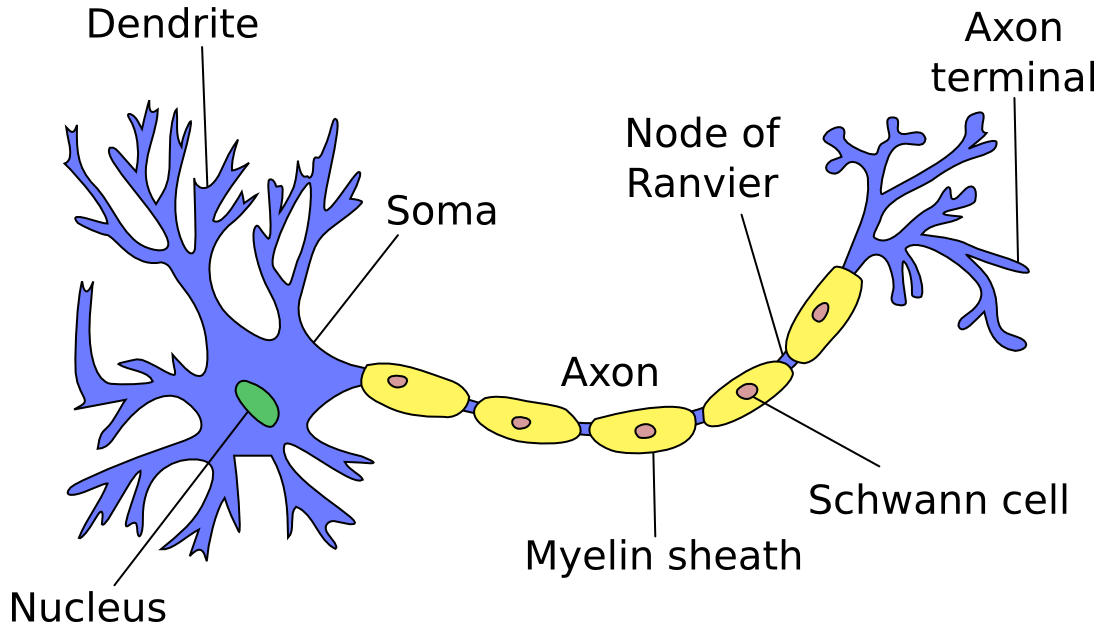
Neurons in artificial neural networks are inspired by biological neurons in nervous systems (shown below). A biological neuron has three main parts: the main body (also known as the soma), dendrites and an axon. There are often many dendrites attached to a neuron body, but only one axon, which can be up to a meter long. In most cases (although there are exceptions), the neuron receives input signals from dendrites, and then outputs its own signals through the axon. Axons in turn connect to the dendrites of other neurons, using special connections called synapses, forming complex neural networks.
Below is an illustration of an artificial neuron, where the input is passed in from the left and the prediction comes out from the right. Each input position has a specific weight in the neuron, and they determine what output to give, given a specific input vector. For example, a neuron could be trained to detect cities. We can then take the vector for London from the previous section, give it as input to our neuron, and it will tell us it’s a city by outputting value 1. If we do the same for the word Tuesday, it will give a 0 instead, meaning that it’s not a city.