In the beginning of August I got the chance to attend the Deep Learning Summer School in Montreal. It consisted of 10 days of talks from some of the most well-known neural network researchers. During this time I learned a lot, way more than I could ever fit into a blog post. Instead of trying to pass on 60 hours worth of neural network knowledge, I have made a list of small interesting nuggets of information that I was able to summarise in a paragraph.
At the moment of writing, the summer school website is still online, along with all the presentation slides. All of the information and most of the illustrations come from these slides and are the work of their original authors. The talks in the summer school were filmed as well, hopefully they will also find their way to the web.
Update: the Deep Learning Summer School videos are now online.
Alright, let’s get started.
1. The need for distributed representations
During his first talk, Yoshua Bengio said “This is my most important slide”. You can see that slide below: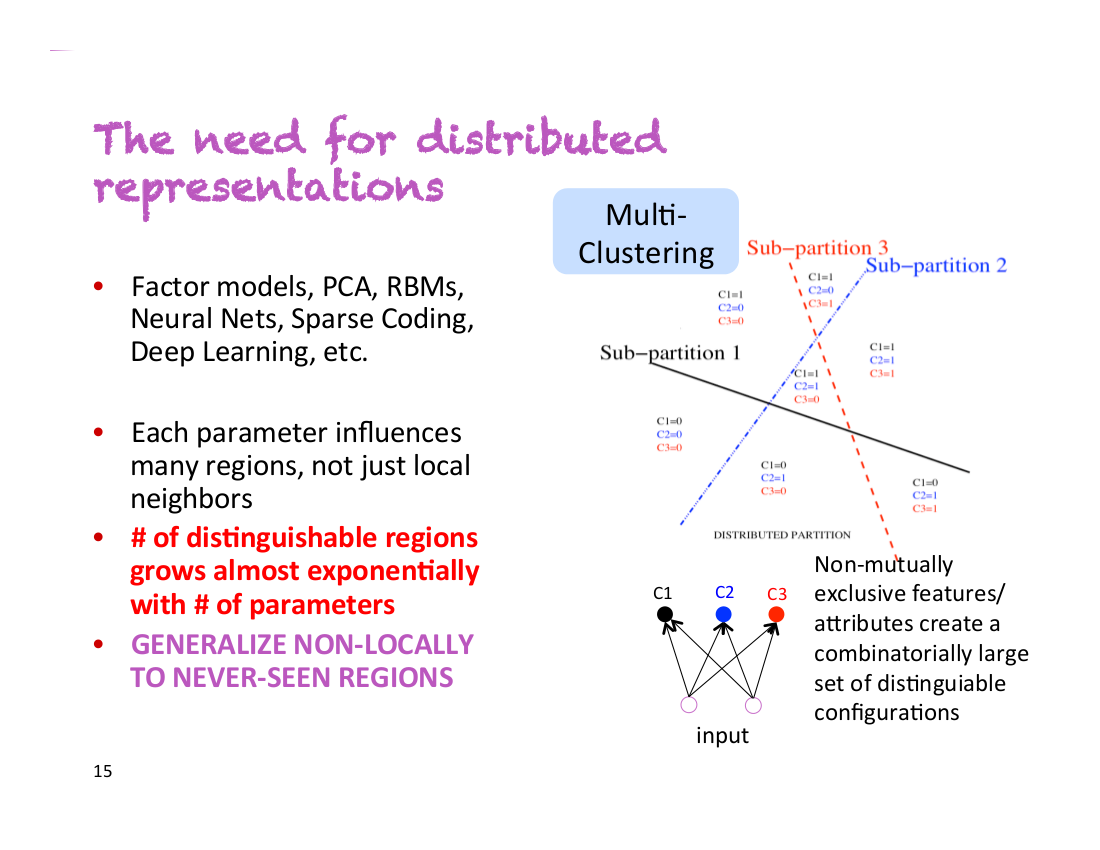
Let’s say you have a classifier that needs to detect people that are male/female, have glasses or don’t have glasses, and are tall/short. With non-distributed representations, you are dealing with 2*2*2=8 different classes of people. In order to train an accurate classifier, you need to have enough training data for each of these 8 classes. However, with distributed representations, each of these properties could be captured by a different dimension. This means that even if your classifier has never encountered tall men with glasses, it would be able to detect them, because it has learned to detect gender, glasses and height independently from all the other examples.