I’m keen to explore some challenges in multimodal learning, such as jointly learning visual and textual semantics. However, I would rather not start by attempting to train an image recognition system from scratch, and prefer to leave this part to researchers who are more experienced in vision and image analysis.
Therefore, the goal is to use an existing image recognition system, in order to extract useful features for a dataset of images, which can then be used as input to a separate machine learning system or neural network. We start with a directory of images, and create a text file containing feature vectors for each image.
1. Install Caffe
Caffe is an open-source neural network library developed in Berkeley, with a focus on image recognition. It can be used to construct and train your own network, or load one of the pretrained models. A web demo is available if you want to test it out.
Follow the installation instructions to compile Caffe. You will need to install quite a few dependencies (Boost, OpenCV, ATLAS, etc), but at least for Ubuntu 14.04 they were all available in public repositories.
Once you’re done, run
make test make runtest
This will run the tests and make sure the installation is working properly.
2. Prepare your dataset
Put all your images you want to process into one directory. Then generate a file containing the path to each image. One image per line. We will use this file to read the images, and it will help you map images to the correct vectors later.
You can run something like this:
find `pwd`/images -type f -exec echo {} \; > images.txt
This will find all files in subdirectory called “images” and write their paths to images.txt
3. Download the model
There are a number of pretrained models publically available for Caffe. Four main models are part of the original Caffe distribution, but more are available in the Model Zoo wiki page, provided by community members and other researchers.
We’ll be using the BVLC GoogLeNet model, which is based on the model described in Going Deeper with Convolutions by Szegedy et al. (2014). It is a 22-layer deep convolutional network, trained on ImageNet data to detect 1,000 different image types. Just for fun, here’s a diragram of the network, rotated 90 degrees:
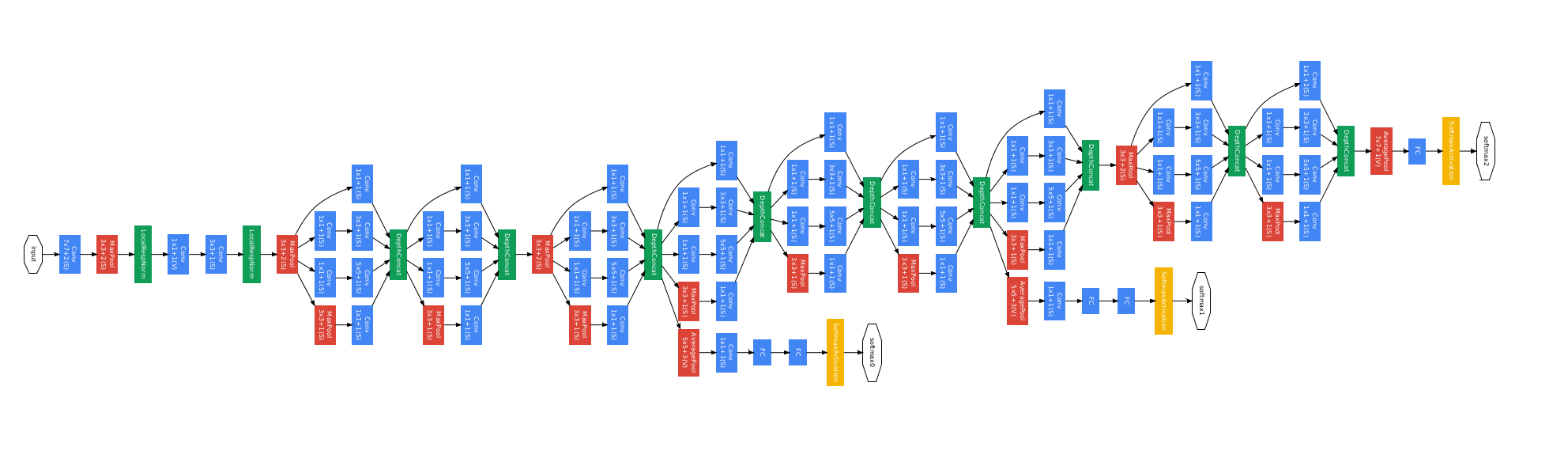
The Caffe models consist of two parts:
- A description of the model (in the form of *.prototxt files)
- The trained parameters of the model (in the form of a *.caffemodel file)
The prototxt files are small, and they came included with the Caffe code. But the parameters are large and need to be downloaded separately. Run the following command in your main Caffe directory to download the parameters for the GoogLeNet model:
python scripts/download_model_binary.py models/bvlc_googlenet
This will find out where to download the caffemodel file, based on information already in the models/bvlc_googlenet/ directory, and will then place it into the same directory.
In addition, run this command as well:
./data/ilsvrc12/get_ilsvrc_aux.sh
It will download some auxiliary files for the ImageNet dataset, including the file of class labels which we will be using later.
4. Process images and print vectors
Now is the time to load the model into Caffe, process each image, and print a corresponding vector into a file. I created a script for that (see below, also available as a Gist):
import numpy as np
import os, sys, getopt
# Main path to your caffe installation
caffe_root = '/path/to/your/caffe/'
# Model prototxt file
model_prototxt = caffe_root + 'models/bvlc_googlenet/deploy.prototxt'
# Model caffemodel file
model_trained = caffe_root + 'models/bvlc_googlenet/bvlc_googlenet.caffemodel'
# File containing the class labels
imagenet_labels = caffe_root + 'data/ilsvrc12/synset_words.txt'
# Path to the mean image (used for input processing)
mean_path = caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy'
# Name of the layer we want to extract
layer_name = 'pool5/7x7_s1'
sys.path.insert(0, caffe_root + 'python')
import caffe
def main(argv):
inputfile = ''
outputfile = ''
try:
opts, args = getopt.getopt(argv,"hi:o:",["ifile=","ofile="])
except getopt.GetoptError:
print 'caffe_feature_extractor.py -i <inputfile> -o <outputfile>'
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print 'caffe_feature_extractor.py -i <inputfile> -o <outputfile>'
sys.exit()
elif opt in ("-i"):
inputfile = arg
elif opt in ("-o"):
outputfile = arg
print 'Reading images from "', inputfile
print 'Writing vectors to "', outputfile
# Setting this to CPU, but feel free to use GPU if you have CUDA installed
caffe.set_mode_cpu()
# Loading the Caffe model, setting preprocessing parameters
net = caffe.Classifier(model_prototxt, model_trained,
mean=np.load(mean_path).mean(1).mean(1),
channel_swap=(2,1,0),
raw_scale=255,
image_dims=(256, 256))
# Loading class labels
with open(imagenet_labels) as f:
labels = f.readlines()
# This prints information about the network layers (names and sizes)
# You can uncomment this, to have a look inside the network and choose which layer to print
#print [(k, v.data.shape) for k, v in net.blobs.items()]
#exit()
# Processing one image at a time, printint predictions and writing the vector to a file
with open(inputfile, 'r') as reader:
with open(outputfile, 'w') as writer:
writer.truncate()
for image_path in reader:
image_path = image_path.strip()
input_image = caffe.io.load_image(image_path)
prediction = net.predict([input_image], oversample=False)
print os.path.basename(image_path), ' : ' , labels[prediction[0].argmax()].strip() , ' (', prediction[0][prediction[0].argmax()] , ')'
np.savetxt(writer, net.blobs[layer_name].data[0].reshape(1,-1), fmt='%.8g')
if __name__ == "__main__":
main(sys.argv[1:])
You will first need to set the caffe_root variable to point to your Caffe installation. Then run it with:
python caffe_feature_extractor.py -i <inputfile> -o <outputfile>
It will first print out a lot of model-specific debugging information, and will then print a line for each input image containing the image name, the label of the most probable class, and the class probability.
flower.jpg : n11939491 daisy ( 0.576037 ) horse.jpg : n02389026 sorrel ( 0.996444 ) beach.jpg : n09428293 seashore, coast, seacoast, sea-coast ( 0.568305 )
At the same time, it will also print vectors into the output file. By default, it will extract the layer pool5/7x7_s1 after processing each image. This is the last layer before the final softmax in the end, and it contains 1024 elements. I haven’t experimented with choosing different layers yet, but this seemed like a reasonable place to start – it should contain all the high-level processing done in the network, but before forcing it to choose a specific class. Feel free to choose a different layer though, just change the corresponding parameter in the script. If you find that specific layers work better, let me know as well.
The outputfile will contain vectors for each image. There will be one line of values for each input image, and every line will contain 1024 values (if you printed the default layer). Mission accomplished!
Troubleshooting
Below are some tips for when you run into problems.
First, it’s worth making sure you have compiled the python bindings in the Caffe directory:
make pycaffe
I was getting some unusual errors when this code was in a subdirectory of the main Caffe folder. After some googling I found that others had similar problems with other projects, and apparently overlapping library names were causing the wrong dependencies to be included. The simple solution was to move this code out of the Caffe directory, and put it somewhere else.
I installed Caffe with CUDA support, and even though I turned GPU support off in the script, it was still complaining when I didn’t set the CUDA path. For example, I run the code like this (you may need to change the paths to match your system):
LD_LIBRARY_PATH=/usr/local/cuda-7.0/lib64/:$LD_LIBRARY_PATH PYTHONPATH=$PYTHONPATH:/path/to/caffe/python python caffe_feature_extractor.py -i images.txt -o vectors.txt
Finally, Caffe is compiled against a specific version of CUDA. I initially had CUDA 6.5 installed, but after upgrading to CUDA 7.0 the Caffe library had to be recompiled.
Epilogue
There you have it – going from images to vectors. Now you can use these vectors to represent your images in various tasks, such as classification, multi-modal learning, or clustering. Ideally, you will probably want to train the whole network on a specific task, including the visual component, but for starters these pretrained vectors should be quite helpful as well.
These instructions and the script are loosely based on Caffe examples on ImageNet classification and filter visualisation. If the code here isn’t doing quite what you want it to, it’s worth looking at these other similar applications.
If you have any suggestions or fixes, let me know and I’ll be happy to incorporate them in this post.
I keep getting the following error:
Traceback (most recent call last):
File “feature_extractor.py”, line 77, in
main(sys.argv[1:])
File “feature_extractor.py”, line 54, in main
image_dims=(256, 256))
File “/home/mil/andrew/caffe/python/caffe/classifier.py”, line 29, in __init__
in_ = self.inputs[0]
IndexError: list index out of range
I’ve check the size of the image, but to no good.
Could you please help me out on this?
Thanks, it was hard to make it work, but it finally did.
Seriously you helped a lot with this post!
i am not able find my feature vectors everythin works fine but when i run this script python caffe_feature_extractor.py -i -o it says ibvalid syntax
please guide me to make it work as i copied the whole code and saved as with the same file name and tried to run it and gave the exact path to my caffe installation but it shows me an error bash: syntax error near unexpected token `newline’
Hi Andrew,
Not really sure what the problem might be, but here are a few things to check:
* Are you passing the input and output files to the script
* Check that you actually have all the model files that the script is referring to:
caffe_root + ‘models/bvlc_googlenet/deploy.prototxt’
caffe_root + ‘models/bvlc_googlenet/bvlc_googlenet.caffemodel’
caffe_root + ‘data/ilsvrc12/synset_words.txt’
caffe_root + ‘python/caffe/imagenet/ilsvrc_2012_mean.npy’
If not, there’s a script that comes with caffe that downloads them.
* You might want to check one of the official caffe demos, to make sure that they work for you
All the best,
Marek
I have caffe and there are no scripts that allow me to download what you are talking about.
The blog post is 4 years old at this point. It is very likely that the Caffe package has changed since then and the instructions here need to be adapted to match that.
any idea why do the code stack on the line ‘caffe.set_mode_cpu()’
(i also tried using gpu instead)
i am not able find my feature vectors everythin works fine but when i run this script python caffe_feature_extractor.py -i -o it says ibvalid syntax
Hi,
Firstly thanks for this work and it extract high level feature but ı want to extract the before layer. How?
Hi,
You’ll simply need to change the layer name in the script. The net.blobs object should contain keys with all the layer names, so you can try printing these to find out what all the names are.
Thank you very much for this post, Marek! I’ve tried it and it’s working great! GPU performance is dramatic in comparison to CPU.
Here are few questions, if you don’t mind:
1. How did you come up with exactly this initialization of caffe.Classifier, its arguments and constants, I mean? Could you please explain the choice of these parameters?
net = caffe.Classifier(model_prototxt, model_trained,
mean=np.load(mean_path).mean(1).mean(1),
channel_swap=(2,1,0),
raw_scale=255,
image_dims=(256, 256))
2. Are there any alternatives to caffe that can extract features from imagenet pre-trained NN? So far I’ve seen this: https://dato.com/learn/gallery/notebooks/build_imagenet_deeplearning.html. But it troubles me that graphlab is not open source. Can this be done with sklearn or similar projects in the field?
3. Your links to examples are dead. Could you please check?
Hi Yuri,
1. These values I just copied from example code that showed how to load this model. Basically it just loads the mean values, sets image dimensions, and swaps channels (because that’s how the model was trained).
2. If you are willing to implement the models yourself, then any library can be used (eg Theano, Torch, etc). But as it stands, the Caffe seems to have the best selection of freely available pretrained image recognition models.
3. Thanks!
Thank you,helped a lot.
Hi, thank you for your post,
I ran the code on 3 images and it gets stuck in
I0305 19:35:28.365692 21315 net.cpp:816] Ignoring source layer data
I0305 19:35:28.420958 21315 net.cpp:816] Ignoring source layer loss
I don’t understand why!
I have the same, but it still seems to write the features to a vector. You can see the output text file increase in size.
Also, If you print the output of the terminal to a log like this:
python caffe_feature_extractor.py -i images.txt -o features.txt > log.log
You can see the labels and the class probabilities etc.
Hi,
I’m getting this error. I checked all the paths and they are fine.
WARNING: Logging before InitGoogleLogging() is written to STDERR
E0405 14:09:37.553680 59974 common.cpp:104] Cannot create Cublas handle. Cublas won’t be available.
E0405 14:09:37.553900 59974 common.cpp:111] Cannot create Curand generator. Curand won’t be available.
[libprotobuf ERROR google/protobuf/text_format.cc:274] Error parsing text-format caffe.NetParameter: 6:15: Message type “caffe.LayerParameter” has no field named “input_param”.
Do you have some ide what could be.
Thanks,
Edana
Hi,
Thanks for writing this post. It’s surely helpful.
Anyway, if I want to extract large data (i.e 100K images or even million), what is the best way to put the input and store the output? How do you think of LMDB or HDF5 for the solution?
Cheers!
Thom
Hi Marek,
thanks for very informative blog post. However I found an error when I tried to replicate the code in this line:
> prediction = net.predict([input_image], oversample=False)
It said that Net does not have predict method.
I found the solution from the notebook, by using this line instead to set the input image
> net.blobs[‘data’].data[…] = transformed_image
and
> net.forward()
to get the prediction result.
Thanks again for this great post!
Perhaps the Caffe commands have changed, it used to work before.
Thanks for the update!
Hi Marek, was just browsing around, love the blog! Just wanted to point interested people towards our new multi-modal feature toolkit, which automates the whole feature extraction process for you: https://github.com/douwekiela/mmfeat. It’s as easy as running extract.py on a bunch of images.
Thanks! Nice toolkit 🙂
what are the best values for raw_scale and image_dims in caffe.Classifier?